定期的に UTAU の文字コード周りで問題が出る感があるので、備忘を兼ねて、分かる範囲でまとめておく。
 Windows 版の UTAU が読み書きするファイルの文字コードは、すべてが Shift-JIS。
Windows 版の UTAU が読み書きするファイルの文字コードは、すべてが Shift-JIS。
Shift-JIS では、半角文字(半角カナ含む)は 1 バイト、全角文字は 2 バイトで表現される。例えば、「ABあ愛」は 1+1+2+2=6 バイトとなる。
 ※通常のユーザーはここを読み飛ばして構わない
※通常のユーザーはここを読み飛ばして構わない
UTAU のメニューバーやダイアログなどのリソース関連文字列は、UTAU.exe 内に Shift-JIS として埋め込まれているようだ(Ver 0.4.18 zip 版)。
 ※通常のユーザーはここを読み飛ばして構わない
※通常のユーザーはここを読み飛ばして構わない
リソース関連以外については、UTAU.exe 内部コードは Unicode(UTF-16-LE)のようだ(Ver 0.4.18 zip 版)。例えば、「プロジェクトは変更されています。変更を保存しますか?」などのメッセージボックスで表示される文字列。
また、このことから、UTAU 実行中にメモリ上に格納される文字列も UTF-16-LE で格納されているものと思われる。
UTF-16 は、すべての文字を 2 バイトで表現する(ホントはすべてじゃないけど細かいことは気にしない)。半角文字も 2 バイトだ。なので、「ABあ愛」は 2+2+2+2=8 バイトとなる。
UTF-16 にも 2 種類あり、通常「Unicode 表」として表記されているのは UTF-16-BE(ビッグエンディアン)。で、UTF-16-BE の 1 バイト目と 2 バイト目を入れ替えたのが UTF-16-LE(リトルエンディアン)。例えば全角カタカナの「プ」は、ユニコード表(16 進数)では 30 D7 の 2 バイトで表されるが、UTAU.exe 内では逆順となり、D7 30 の 2 バイトで表される。
逆になるのは非常に分かりづらいが、これは UTAU の問題ではなく、Intel CPU の伝統なので受け入れるしかない。
 UTF-16-LE は Shift-JIS との互換性は一切なく、両者で同じ文字コードをを使っている文字は無い。
UTF-16-LE は Shift-JIS との互換性は一切なく、両者で同じ文字コードをを使っている文字は無い。
しかし、バイト列レベルで見ると、半角英数については類似性があり、Shift-JIS のコードにゼロを付加した物が UTF-16-LE となる。例えば「ABC」は Shift-JIS だと 16 進数で 41 42 43 の 3 バイトとなるが、UTF-16-LE だと 41 00 42 00 43 00 の 6 バイトとなる。このため、半角英数を UTF-16-LE で保存して、Shift-JIS だと思って開くと、間延びしたように表示される(右の図をクリックして確認してほしい)。
また、プログラミングの視点で見ると、0x00 を文字列の終端と見なす C 言語などでは、何も考えずに UTF-16-LE の文字列を読み込むと、途中に出現する 0x00 のせいで、文字列が途切れてしまうことがあり、注意が必要となる。
oto.ini と prefix.map が用いる UTF-8 では、半角英数は 1 バイト、日本語はたいてい 3 バイトとなる。半角カナも 3 バイト。例えば、「ABあ愛」は 1+1+3+3=8 バイトとなる。
UTF-8 と Shift-JIS は、半角英数は同じコードを使っている。つまり、半角英数だけのファイルなら、UTF-8 として扱う UTAU-Synth でも、Shift-JIS として扱う UTAU でも、問題なく開ける。
oto.ini / prefix.map 以外は UTAU-Synth も Shift-JIS なので、UTAU とファイルを共用できることになる。ただし、Windows の Shift-JIS と Mac の Shift-JIS は方言のようなものが多少異なり、一部の文字に互換性が無い。通常使う範囲ではあまり問題にならないが、記号類は避けた方が良いだろう。
この記事でも混同して使っているが、厳密には、文字コードを考える時には、「キャラクターセット」と「エンコーディング」の 2 つに分けて考える必要がある。
キャラクターセットは、「どんな文字を取り扱うか(文字集合)」で、例えば欧米ならアルファベットだけでいいよ、とか、日本なら漢字も入れたいね、という話になる。
エンコーディングは、キャラクターセットで扱う文字を、具体的にどんなバイト列で表現するかを決める。
Shift-JIS の場合は、キャラクターセットとエンコーディングがセットになっている感じなので、キャラクターセットやエンコーディングを意識しなくて良い。
UTF-16-LE と UTF-8 は両方とも、キャラクターセットとしては世界中の文字を扱う Unicode で同じある。同じ文字を、どのようにバイト列にするかの規則(エンコーディング)が違うにすぎない。
UTF-16-LE は「すべて 2 バイト」という処理しやすい規則になっている。一方 UTF-8 は、半角英数という最もよく使われる文字を 1 バイトにして、容量の節約を図っている。同じキャラクターセットを表現するにしても、用途によって適したエンコーディングが変わる、という話である。
- Windows 版 UTAU
- Windows 版 UTAU の内部コード(メニュー・ダイアログ関連)
- Windows 版 UTAU の内部コード(メニュー・ダイアログ以外)
- Mac 版 UTAU(UTAU-Synth)
- おまけ知識
- 参考リンク
Windows 版 UTAU
 Windows 版の UTAU が読み書きするファイルの文字コードは、すべてが Shift-JIS。
Windows 版の UTAU が読み書きするファイルの文字コードは、すべてが Shift-JIS。- ust
- oto.ini
- prefix.map
- character.txt
- setting.ini
- 音声合成時のバッチファイル
Shift-JIS では、半角文字(半角カナ含む)は 1 バイト、全角文字は 2 バイトで表現される。例えば、「ABあ愛」は 1+1+2+2=6 バイトとなる。
Windows 版 UTAU の内部コード(メニュー・ダイアログ関連)
 ※通常のユーザーはここを読み飛ばして構わない
※通常のユーザーはここを読み飛ばして構わないUTAU のメニューバーやダイアログなどのリソース関連文字列は、UTAU.exe 内に Shift-JIS として埋め込まれているようだ(Ver 0.4.18 zip 版)。
- ファイル→名前をつけて保存
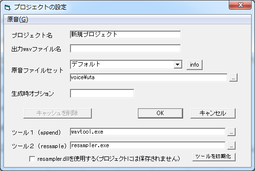
- プロジェクトの設定ダイアログ→プロジェクト名
Windows 版 UTAU の内部コード(メニュー・ダイアログ以外)
 ※通常のユーザーはここを読み飛ばして構わない
※通常のユーザーはここを読み飛ばして構わないリソース関連以外については、UTAU.exe 内部コードは Unicode(UTF-16-LE)のようだ(Ver 0.4.18 zip 版)。例えば、「プロジェクトは変更されています。変更を保存しますか?」などのメッセージボックスで表示される文字列。
また、このことから、UTAU 実行中にメモリ上に格納される文字列も UTF-16-LE で格納されているものと思われる。
UTF-16 は、すべての文字を 2 バイトで表現する(ホントはすべてじゃないけど細かいことは気にしない)。半角文字も 2 バイトだ。なので、「ABあ愛」は 2+2+2+2=8 バイトとなる。
UTF-16 にも 2 種類あり、通常「Unicode 表」として表記されているのは UTF-16-BE(ビッグエンディアン)。で、UTF-16-BE の 1 バイト目と 2 バイト目を入れ替えたのが UTF-16-LE(リトルエンディアン)。例えば全角カタカナの「プ」は、ユニコード表(16 進数)では 30 D7 の 2 バイトで表されるが、UTAU.exe 内では逆順となり、D7 30 の 2 バイトで表される。
逆になるのは非常に分かりづらいが、これは UTAU の問題ではなく、Intel CPU の伝統なので受け入れるしかない。
 UTF-16-LE は Shift-JIS との互換性は一切なく、両者で同じ文字コードをを使っている文字は無い。
UTF-16-LE は Shift-JIS との互換性は一切なく、両者で同じ文字コードをを使っている文字は無い。しかし、バイト列レベルで見ると、半角英数については類似性があり、Shift-JIS のコードにゼロを付加した物が UTF-16-LE となる。例えば「ABC」は Shift-JIS だと 16 進数で 41 42 43 の 3 バイトとなるが、UTF-16-LE だと 41 00 42 00 43 00 の 6 バイトとなる。このため、半角英数を UTF-16-LE で保存して、Shift-JIS だと思って開くと、間延びしたように表示される(右の図をクリックして確認してほしい)。
また、プログラミングの視点で見ると、0x00 を文字列の終端と見なす C 言語などでは、何も考えずに UTF-16-LE の文字列を読み込むと、途中に出現する 0x00 のせいで、文字列が途切れてしまうことがあり、注意が必要となる。
Mac 版 UTAU(UTAU-Synth)
UTAU-Synth はよくわからないが、どうやら、oto.ini と prefix.map は UTF-8、それ以外のファイルは Shift-JIS で出力するようになっている模様。oto.ini と prefix.map が用いる UTF-8 では、半角英数は 1 バイト、日本語はたいてい 3 バイトとなる。半角カナも 3 バイト。例えば、「ABあ愛」は 1+1+3+3=8 バイトとなる。
UTF-8 と Shift-JIS は、半角英数は同じコードを使っている。つまり、半角英数だけのファイルなら、UTF-8 として扱う UTAU-Synth でも、Shift-JIS として扱う UTAU でも、問題なく開ける。
oto.ini / prefix.map 以外は UTAU-Synth も Shift-JIS なので、UTAU とファイルを共用できることになる。ただし、Windows の Shift-JIS と Mac の Shift-JIS は方言のようなものが多少異なり、一部の文字に互換性が無い。通常使う範囲ではあまり問題にならないが、記号類は避けた方が良いだろう。
おまけ知識
※通常のユーザーはここを読み飛ばして構わないこの記事でも混同して使っているが、厳密には、文字コードを考える時には、「キャラクターセット」と「エンコーディング」の 2 つに分けて考える必要がある。
キャラクターセットは、「どんな文字を取り扱うか(文字集合)」で、例えば欧米ならアルファベットだけでいいよ、とか、日本なら漢字も入れたいね、という話になる。
エンコーディングは、キャラクターセットで扱う文字を、具体的にどんなバイト列で表現するかを決める。
Shift-JIS の場合は、キャラクターセットとエンコーディングがセットになっている感じなので、キャラクターセットやエンコーディングを意識しなくて良い。
UTF-16-LE と UTF-8 は両方とも、キャラクターセットとしては世界中の文字を扱う Unicode で同じある。同じ文字を、どのようにバイト列にするかの規則(エンコーディング)が違うにすぎない。
UTF-16-LE は「すべて 2 バイト」という処理しやすい規則になっている。一方 UTF-8 は、半角英数という最もよく使われる文字を 1 バイトにして、容量の節約を図っている。同じキャラクターセットを表現するにしても、用途によって適したエンコーディングが変わる、という話である。
